CompTIA Security+ SY0-601 Course
-
About the course and exam
About the course and certification -
About the course author
-
Pre-requisites
-
Tools and tips to help you study more efficiently
-
Study techniques that will help you pass
-
What surprised me the most about the exam
-
Domain 1: Threats, Attacks, and VulnerabilitiesAbout threats, attacks, and vulnerabilities
-
1.1: Compare and contrast social engineering techniquesWhat is social engineering?
-
Principles
-
Spam
-
Blocking and Managing Spam
-
Phishing
-
Smishing
-
Vishing
-
Spear Phishing
-
Whaling
-
Impersonation
-
Dumpster diving
-
Shoulder surfing
-
Pharming
-
Tailgating
-
Eliciting information
-
Prepending
-
Identity fraud
-
Invoice scams
-
Credentials harvesting
-
Reconnaissance
-
Hoax
-
Watering hole attack
-
Typo squatting and URL hijacking
-
Influence campaigns
-
Hybrid warfare
-
Practical knowledge check
-
1.2: Analyze potential indicators to determine the type of attackWhat is malware?
-
Malware classification
-
Virus
-
Worms
-
Backdoor
-
Trojans
-
Remote Access Trojan (RAT)
-
Ransomware and Crypto Malware
-
How does ransomware work?
-
Potentially unwanted programs (PUPs)
-
Spyware
-
Adware and Malvertising
-
Keyloggers
-
Fileless malware
-
Logic bombs
-
Rootkit
-
Bots and Botnets
-
Command and control
-
What are password attacks?
-
Plaintext, encrypted, and hashed passwords
-
Brute force
-
Dictionary attacks
-
Spraying attacks
-
Rainbow and hash tables
-
Credential stuffing
-
What are physical attacks?
-
Malicious universal serial bus (USB) cable
-
Malicious flash drive
-
Card cloning
-
Skimming
-
What is adversarial AI and tainted training for ML?
-
Supply-chain attacks
-
Cloud-based vs. on-premises attacks
-
Cryptography concepts
-
Cryptographic attacks
-
Quiz: 1.23 Quizzes
-
1.3: Analyze potential indicators associated with application attacksPrivilege escalation
-
Improper input handling
-
Improper error handling
-
Cross-Site Scripting (XSS)
-
Structured Query Language (SQL) injections
-
Dynamic Link Library (DLL) Injections
-
Lightweight directory access protocol (LDAP) Injections
-
Extensible Markup Language (XML) and XPATH Injections
-
XXE Injections
-
Directory traversal
-
Request forgeries (server-side, client-side, and cross-site)
-
Application Programming Interface (API) attacks
-
Secure Sockets Layer (SSL) stripping
-
Replay attacks (session replays)
-
Pass the hash
-
Race conditions (time of check and time of use)
-
Resource exhaustion
-
Memory leak
-
Pointer/object dereference
-
Integer overflow
-
Buffer overflows
-
Driver manipulation (shimming and refactoring)
-
Quiz 1.32 Quizzes
-
1.4: Analyze potential indicators of network attacksWhat are wireless attacks?
-
Distributed Denial of Service (DDoS)
-
Rogue access point and Evil Twin
-
Bluesnarfing and Bluejacking
-
Disassociation and Jamming
-
Radio Frequency Identifier (RFID) attacks
-
Near Field Communication (NFC)
-
Initialization Vector (IV)
-
Man in the middle (on-path)
-
Man in the browser (on-path browser)
-
What are layer 2 attacks?
-
Address resolution protocol (ARP)
-
Media access control (MAC) flooding
-
MAC cloning
-
What are Domain Name System (DNS) attacks and defenses?
-
Domain hijacking
-
DNS poisoning
-
Universal resource locator (URL) redirection
-
Domain reputation
-
Quiz 1.41 Quiz
-
1.5: Explain threat actors, vectors, and intelligence sourcesWhat are actors and threats?
-
Attributes of actors
-
Vectors
-
Insider threats
-
State actors
-
Hacktivists
-
Script kiddies
-
Hackers (white hat, black hat, gray hat)
-
Criminal syndicates
-
Advanced persistent threats (APTs)
-
Shadow IT
-
Competitors
-
Threat intelligence sources (OSINT and others)
-
Using threat intelligence
-
Research sources
-
Quiz 1.51 Quiz
-
1.6: Security concerns associated with various vulnerabilitiesCloud-based vs. on-premises vulnerabilities
-
Zero-day vulnerabilities
-
Weak configurations
-
Weak encryption, hashing, and digital signatures
-
Third-party risks
-
Improper or weak patch management
-
Legacy platforms
-
Impacts
-
Quiz 1.61 Quiz
-
1.7: Summarizing techniques used in security assessmentsThreat hunting
-
Vulnerability scans
-
Security information and event management (SIEM) and Syslog
-
Security orchestration, automation, and response (SOAR)
-
Quiz 1.71 Quiz
-
1.8: Explaining techniques used in penetration testingImportant pentesting concepts
-
Bug bounties
-
Exercise types (red, blue, white, and purple teams)
-
Passive and active reconnaissance
-
Quiz 1.81 Quiz
-
Domain 2: Architecture and DesignAbout architecture and design
-
2.1: Explaining the importance of security concepts in an enterprise environmentConfiguration management
-
Data sovereignty
-
Data protection
-
Hardware security module (HSM) and Trusted Platform Module (TPM)
-
Geographical considerations
-
Cloud access security broker (CASB)
-
Response and recovery controls
-
Secure Sockets Layer (SSL) and Transport Layer Security (TLS) inspection
-
Hashing
-
API considerations
-
Site resiliency
-
Deception and disruption
-
Quiz 2.11 Quiz
-
2.2: Virtualization and cloud computing conceptsComparing cloud models
-
Cloud service providers
-
Virtualization
-
Containers
-
Microservices and APIs
-
Serverless architecture
-
MSPs and MSSPs
-
On-premises vs. off-premises
-
Edge computing
-
Fog computing
-
Thin client
-
Infrastructure as Code
-
Services integration
-
Resource policies
-
Transit gateway
-
Quiz 2.21 Quiz
-
2.3: Secure application development, deployment, and automation conceptsUnderstanding development environments
-
Automation and scripting
-
Version control
-
Secure coding techniques
-
Open Web Application Security Project (OWASP)
-
Integrity measurement
-
Software diversity
-
Provisioning and deprovisioning
-
Elasticity
-
Scalability
-
Quiz 2.31 Quiz
-
2.4: Authentication and authorization design conceptsImportant authentication and authorization concepts
-
Multifactor authentication (MFA) factors and attributes
-
Quiz: MFA factors and attributes1 Quiz
-
Authentication technologies
-
Biometrics techniques and concepts
-
Authentication, authorization, and accounting (AAA)
-
Cloud vs. on-premises requirements
-
Quiz 2.41 Quiz
-
2.5: Implementing cybersecurity resilienceWhat is redundancy?
-
Disk redundancy (RAID levels)
-
Network redundancy
-
Power redundancy
-
Replication
-
Backup types (full, incremental, differential, and snapshot)
-
Backup types practice scenarios
-
Backup devices and strategies
-
Quiz: Backup types, devices, and strategies1 Quiz
-
Non-persistence
-
Restoration order
-
Diversity
-
Quiz 2.51 Quiz
-
2.6: Security implications of embedded and specialized systemsWhat are embedded systems?
-
System on a Chip (SoC)
-
SCADA and ICS
-
Internet of Things (IoT)
-
Specialized systems
-
VoIP, HVAC, Drones/AVs, MFP, RTOS, Surveillance systems
-
Communication considerations
-
Important constraints
-
2.7: Importance of physical security controlsBollards/barricades, Mantraps, Badges, Alarms, Signage
-
Lighting and fencing
-
Cameras and Closed-circuit television (CCTV)
-
Industrial camouflage
-
Personnel, robots, drones/UAVs
-
Locks
-
Different sensors
-
Fire suppression
-
Protected cable distribution (PCD)
-
Secure areas (air gap, faraday cages, DMZ, etc…)
-
Hot and cold aisles
-
Secure data destruction
-
USB data blocker
-
Quiz 2.71 Quiz
-
2.8: Basics of cryptographyCommon use cases
-
Key length
-
Key stretching
-
Salting, hashing, digital signatures
-
Perfect forward secrecy
-
Elliptic curve cryptography
-
Ephemeral
-
Symmetric vs. asymmetric encryption
-
Key exchange
-
Cipher suites
-
Modes of operation
-
Lightweight cryptography and Homomorphic encryption
-
Steganography
-
Blockchain
-
Quantum and post-quantum
-
Limitations
-
Quizzes 2.82 Quizzes
-
Domain 3: ImplementationAbout implementation
-
3.1: Implement Secure ProtocolsImportant protocols to know and use cases
-
Important email secure protocols
-
IPsec and VPN
-
FTPS, SFTP, SCP
-
DNSSEC
-
SRTP and NTPsec
-
DHCP
-
SNMP and SNMPv3
-
Quiz 3.11 Quiz
-
3.2: Implement host or application security solutionsEndpoint protection
-
Self-encrypting drive (SED), full disk encryption (FDE), and file-level encryption
-
Boot integrity
-
Database and data security
-
Application security
-
Hardening hosts
-
Sandboxing
-
Quiz 3.21 Quiz
-
3.3: Implement secure network designsDNS
-
Load balancing
-
Network segmentation
-
East-West and North-South
-
Jump servers (bastion hosts)
-
Network Address Translation (NAT) Gateway
-
Proxy servers
-
Out-of-band management
-
Quiz 3.3.11 Quiz
-
Virtual Private Networks (VPNs) and IPsec
-
Network Access Control (NAC)
-
Port security
-
Network-based intrusion detection system (NIDS) and network-based intrusion prevention system (NIPS)
-
Firewalls
-
Next-Generation Firewalls
-
Access Control List (ACL) and Security Groups (SGs)
-
Quiz 3.3.21 Quiz
-
Quality of Service (QoS)
-
Implications of IPv6
-
Port scanning and port mirroring
-
File integrity monitors
-
Quiz 3.3.31 Quiz
-
3.4: Install and configure wireless security settingsCryptographic protocols
-
Methods
-
Authentication protocols
-
Installation considerations
-
Quiz 3.41 Quiz
-
3.5: Implement secure mobile solutionsConnection methods and receivers
-
Mobile deployment models
-
Mobile device management (MDM)
-
Mobile devices
-
Enforcement and monitoring
-
Quiz 3.51 Quiz
-
3.6: Apply cybersecurity solutions to the cloudCloud security controls
-
Secure cloud storage
-
Secure cloud networking
-
Secure cloud compute resources
-
Secure cloud solutions
-
Quiz 3.61 Quiz
-
3.7: Implement identity and account management controlsUnderstanding identity
-
Account types to consider
-
Account policies to consider
-
Quiz 3.71 Quiz
-
3.8: Implement authentication and authorization solutionsAuthentication management
-
Authentication protocols and considerations
-
Extensible Authentication Protocol (EAP)
-
RADIUS and TACACS+
-
Kerberos, LDAP, and NTLM
-
Federated Identities
-
Access control schemes
-
Recap notes from this section
-
Quiz 3.81 Quiz
-
3.9: Implement public key infrastructureWhat is public key infrastructure?
-
Types of certificates
-
Certificate formats
-
Important concepts
-
Quiz 3.91 Quiz
-
4.0: Operations and Incident ResponseAbout operations and incident response
-
4.1: Use the appropriate tools to assess organizational securityNetwork reconnaissance and discovery part 1
-
Network reconnaissance and discovery part 2
-
File manipulation
-
Shell and script environments
-
Packet capture and replay
-
Forensics tools
-
Exploitation frameworks
-
Password crackers
-
Data sanitization
-
Quiz 4.11 Quiz
-
4.2: Policies, processes, and procedures for incident responseIncident response plans
-
Incident response process
-
Important exercises
-
Important attack frameworks
-
BCP, COOP, and DRP
-
Incident response team and stakeholder management
-
Retention policies
-
Quiz 4.21 Quiz
-
4.3: Using appropriate data sources to support investigations after an incidentVulnerability scan outputs
-
SIEM dashboards
-
Log files
-
Syslog, rsyslog, syslog-ng
-
Journald and journalctl
-
NXLog
-
Bandwidth and network monitors
-
Important and useful metadata
-
Quiz 4.31 Quiz
-
4.4: Applying mitigation techniques or controls to secure environments during an incidentReconfiguring endpoint security solutions
-
Configuration changes
-
Isolation, containment, and segmentation
-
Secure Orchestration, Automation, and Response (SOAR)
-
Quiz 4.41 Quiz
-
4.5: Key aspects of digital forensicsDocumentation and evidence
-
E-discovery, data recovery, and non-repudiation
-
Integrity and preservation of information
-
Acquisition
-
On-premises vs. cloud
-
Strategic intelligence and counterintelligence
-
Quiz 4.51 Quiz
-
Domain 5: Governance, Risk, and ComplianceAbout governance, risk and compliance
-
5.1: Compare and contrast various types of controlsCategories
-
Control types
-
Quiz 5.11 Quiz
-
5.2: Applicable regulations, standards, or frameworks that impact organizational security postureRegulations, standards, and legislation
-
Key frameworks to know about
-
Benchmarks and secure configuration guides
-
Quiz 5.21 Quiz
-
5.3: Importance of policies to organizational securityPersonnel
-
User training
-
Third-party risk management
-
Data
-
Credential policies
-
Organizational policies
-
Quiz 5.31 Quiz
-
5.4 Risk management processes and conceptsTypes of risks
-
Risk management strategies
-
Risk analysis
-
Disasters
-
Business impact analysis
-
Quiz 5.41 Quiz
-
5.5: Privacy and sensitive data concepts in relation to securityOrganizational consequences of privacy breaches
-
Notifications of breaches
-
Data types
-
Privacy enhancing technologies
-
Roles and responsibilities
-
Quiz 5.51 Quiz
-
Course Recap and Next StepsLooking for the practice exams?
-
Receiving your Certificate of Completion

This lesson isn’t a requirement for the CompTIA Security+ exam, meaning that we’re going beyond the scope of this exam for a few minutes, but I wanted to include it because I believe that this is helpful and practical knowledge that you can apply to your personal life but also on the job. So if you’re not interested, feel free to complete this lesson and move on to the next, but if you are interested, let’s dive in.
Understanding malware classification
Let’s talk about understanding malware classification.
Whenever an anti-virus or anti-malware tool detects something potentially malicious, it uses a specific type of format to help you or other professionals know exactly what kind of threat you are dealing with. The format might look a little bit like this:
Type:Platform/Family.Variant!Suffixes
It won’t always look exactly like this, because as you’ll remember, not every company or tool uses the same standards, but in general, they all look pretty similar.
This format is referred to as the Computer Antivirus Research Organization (CARO) malware naming scheme, and it’s been widely adopted, even if with slight variations, just like we talked about.
For example, here are some real examples:
HEUR:Backdoor.MSIL.Broide.gen
Trojan.MSIL.Broide.m!c
Code language: CSS (css)Both of those are actually the same malware that was detected in a scan, but recognized by different tools. As you can see, it’s talking about the same malware, it’s just labeling it a tad differently.
The first label is being more specific by saying that it’s a Backdoor Trojan, while the second just says Trojan.
Let’s break it down a bit further
Type
The type of malware — which is the first thing you’ll see, helps provide an initial overview of what threat you are dealing with. Is it a type of trojan? Is it a virus? Is it a worm or backdoor or ransomware?
This label helps define that.
Platform
Next, we have the platform classification. This is used to describe the operating system that this threat is designed to work on, like specific to Windows, Linux, Android, or MacOS versions.
It can also be used to describe programming languages, macros, or file types.
In our prior example, MSIL stands for Microsoft Intermediate Language.
Family
The family classification tends to be a bit all over the place, but it’s used to try and differentiate between malware that shares a common code base.
For example, if you’ve ever heard the terms “WannaCry,” “Stuxnet,” or even “CryptoLocker,” these names do not represent types of malware — they are family names.
Stuxnet is considered a worm because of what it was designed to do. It’s obviously not the first worm to ever have existed, but it was developed in such a way that made it unique. When it was identified and researched after having been used, researchers decided to give it a family name of Stuxnet.
Variant
We also have variants. Following along with our Stuxnet example, if someone were to grab the original implementation of Stuxnet and make a few modifications, meaning that it essentially shared the same codebase with a few differences, then that would become a variant of Stuxnet.
Without getting even further into the weeds, family and variant information can be different when talking about detection versus identification of malware.
For example, detection software will typically use incremental letters and numbers or even hashes to set the variant, while malware identifiers may use actual names.
Malware named Stars, Flame, and Nitro Zeus are examples of what’s thought to be variants of Stuxnet. But if software were to detect those variants, it would probably use incremental letters, numbers, or hashes to describe them.
Suffixes
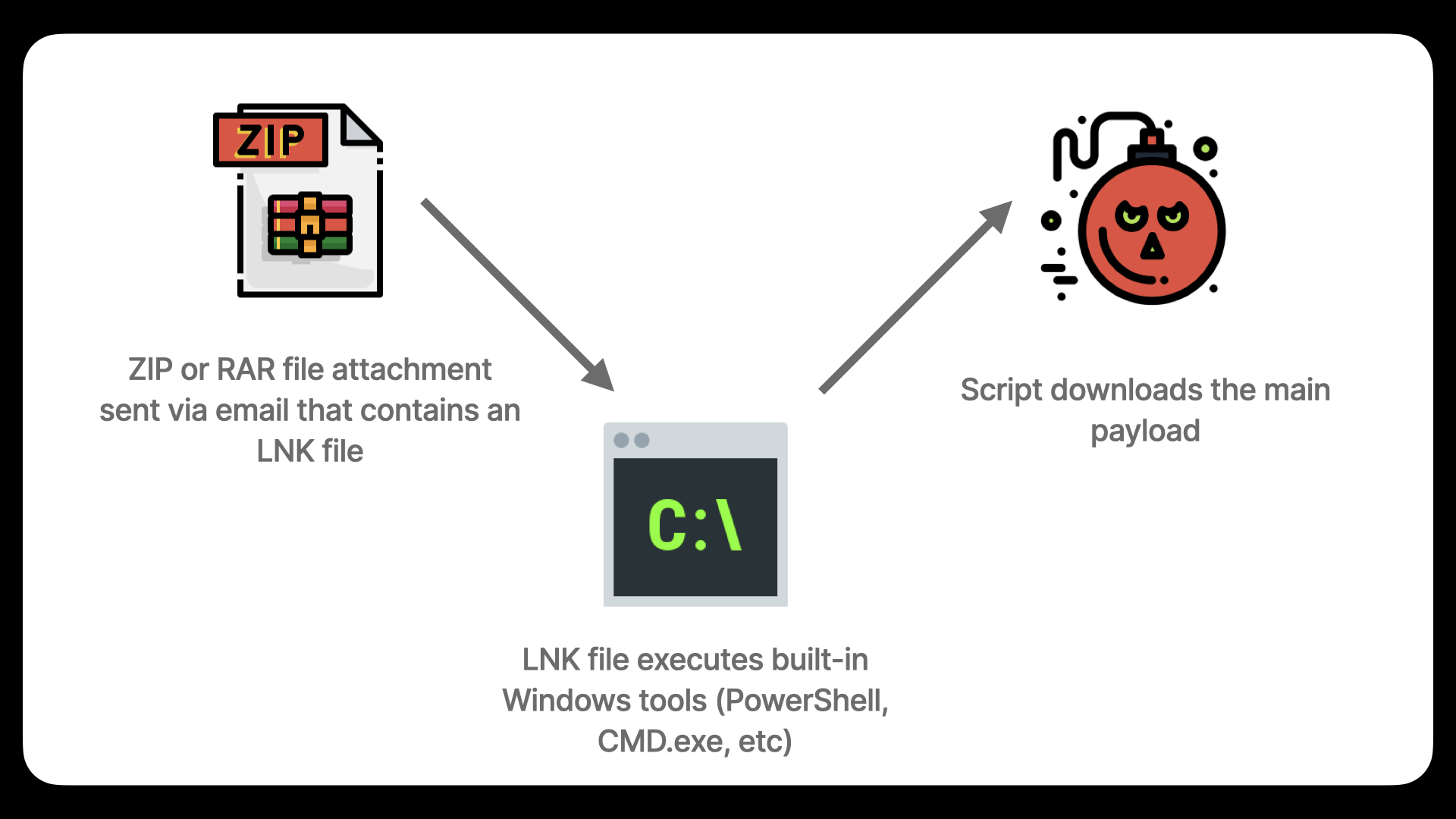
Finally, we have suffixes. Suffixes are used to provide additional details about a specific threat. For example, suffixes can be used to denote how a specific malware threat is packaged. Is it compressed? If so, it may have a suffix of !lnk if it uses that file format, which is a Windows extension which can be used to execute Powershell scripts, and those Powershell scripts could be used to download the malware itself while evading detection.
Or, as another example, a suffix might be .DLL, which represents malware that uses DLLs. DLL stands for Dynamic Link Library, which is just a simple file extension that can be used by applications in Windows to enhance functionality. In fact, if you were to browse through applications that you use on a daily basis, you would likely see a large number of DLL files stored on your computer.
Malware can use the DLL format to get transported and then executed, and in those cases, detection software may add the .DLL suffix to represent that.
Conclusion
Keep in mind that different vendors will sometimes change how they use or display this type of information. Unfortunately, there doesn’t seem to be any updated convention that everyone uses and sticks to, and it often feels like a pretty big mess. It certainly doesn’t help the media, which then amplifies the problem by commonly misusing terms or classifications, which then confuses everybody else.
All that to say — it’s entirely possible that you’ll come across different formats over time. With that said, hopefully this gave you a general sense of how to read and understand this type of information, especially as we move along and discuss malware in more detail.
While you don’t have to understand this for the exam, I thought it would be a good addition to the course because it is very useful knowledge to have.
Reference Material
- More on malware naming: https://docs.microsoft.com/en-us/windows/security/threat-protection/intelligence/malware-naming
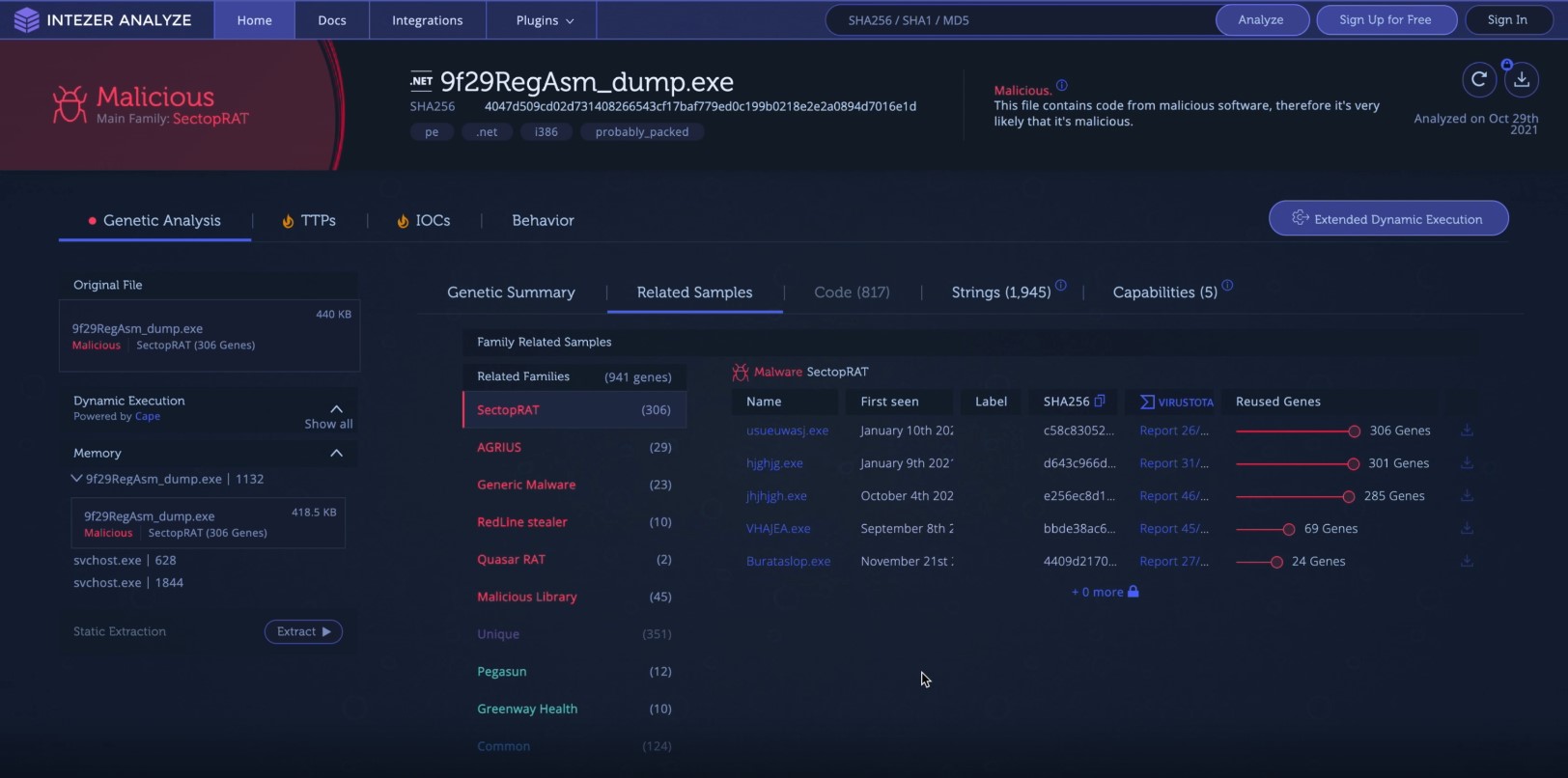
- Malware family, variants, and signatures examples: https://analyze.intezer.com/analyses/e601743b-7d74-4b90-9914-74a1b1de088b
- Example malware detection used in this lesson: https://www.virustotal.com/gui/file/c58c8305284b7002bc4edfa8e311ee59cad74ee61aae3011e0420379409abfa6
Responses