How I made my Python subnet calculator more efficient with 40% less code
I originally built a Python subnet calculator which takes user input for two IP addresses and a corresponding subnet mask in CIDR /30 – /24 to calculate whether the provided IP addresses can reside in the subnet created by the selected subnet mask.
However, after further refactoring, I found ways to not only improve the Python subnet calculator’s efficiency, but also to increase functionality — all with 40% less code.
For this article, I will be comparing both versions side-by-side to explain how I achieved these results. Both versions are available on my GitHub with my other various projects. Version 2.0 is the new and improved version where I was able to go back to the project and simplify it close to half it’s original size!
Getting started with refactoring the Python subnet calculator
To start out, go to my GitHub to download the Python subnet calculator project and review the READMEs provided. This will ensure proper steps have been taken to minimize issues or errors from missing dependencies.
After that, proceed to open both versions (sameSubnet.py & same_subnet2.0.py) in the Twolps_SameNetwork and Twolps_SameNetwork2.0 directories.
Open a text editor that can split the screen to view multiple projects. To achieve this I personally enjoy Sublime Text, in this editor screen splitting is achieved by holding shift + alt and pressing 2 (goes up to 5 for options).
For reference in the screenshots below, the newer is on the left while the older version is placed on the right.
Improving the main section
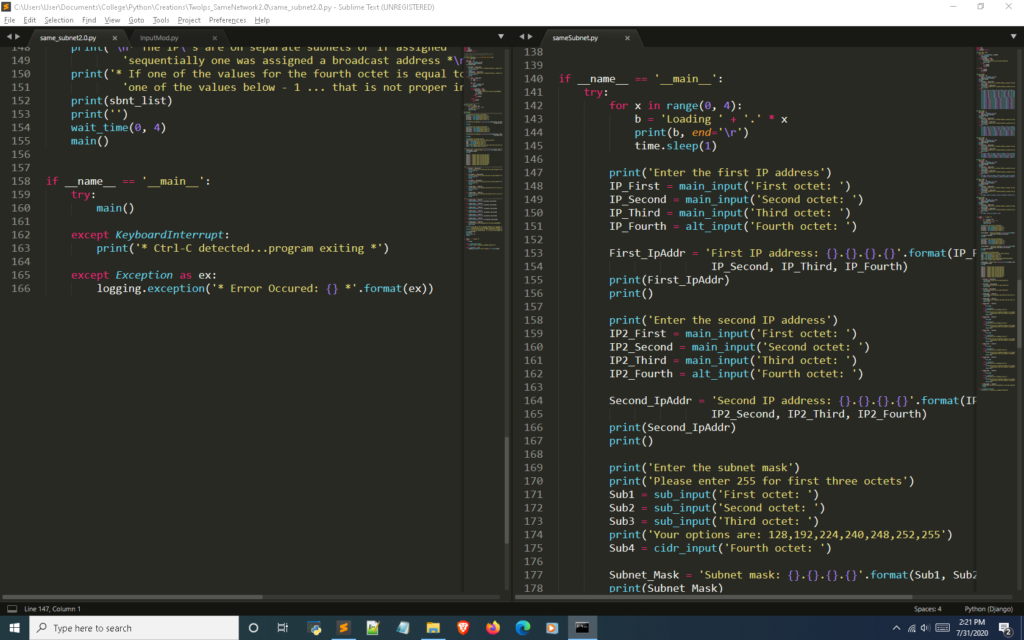
I want to start off by observing the structure of the main part of the Python subnet calculator. As the screenshot shows below, both programs’ starting point is at the if __name__ == '__main__': statement.
This statement confirms that your code is being run as the main program and is essential when working with modules. It also marks the starting point where the code will execute. I have heard though various sources that failing to use this statement with modules can cause buggy issues and even system crashes from race conditions. Doing this will increase modularity since the functions then can be used in other programs.
Now after that initial statement the main section looks significantly different though they operate in a similar manner.
This is because the newer version’s main section is put into a function. The reason why I would do such a thing is because it makes it very easy to loop back the beginning of a program after an invalid input rather then exciting and having to restart in the terminal.
The other benefit for having main in a function nested in a try - except statement is that it provides global error handling using the logging module to show the full stack trace if an error occurs (or it can be logged to a file to keep the program moving).
It also provides a global exit point if the users decides to leave.
The global logging with the full stack trace is easy and efficient for developing but could pose a security threat if it is code is intended for general users such as an application. If that is the case remove it and use lower verbosity and make the error messages as vague as effectively possible.
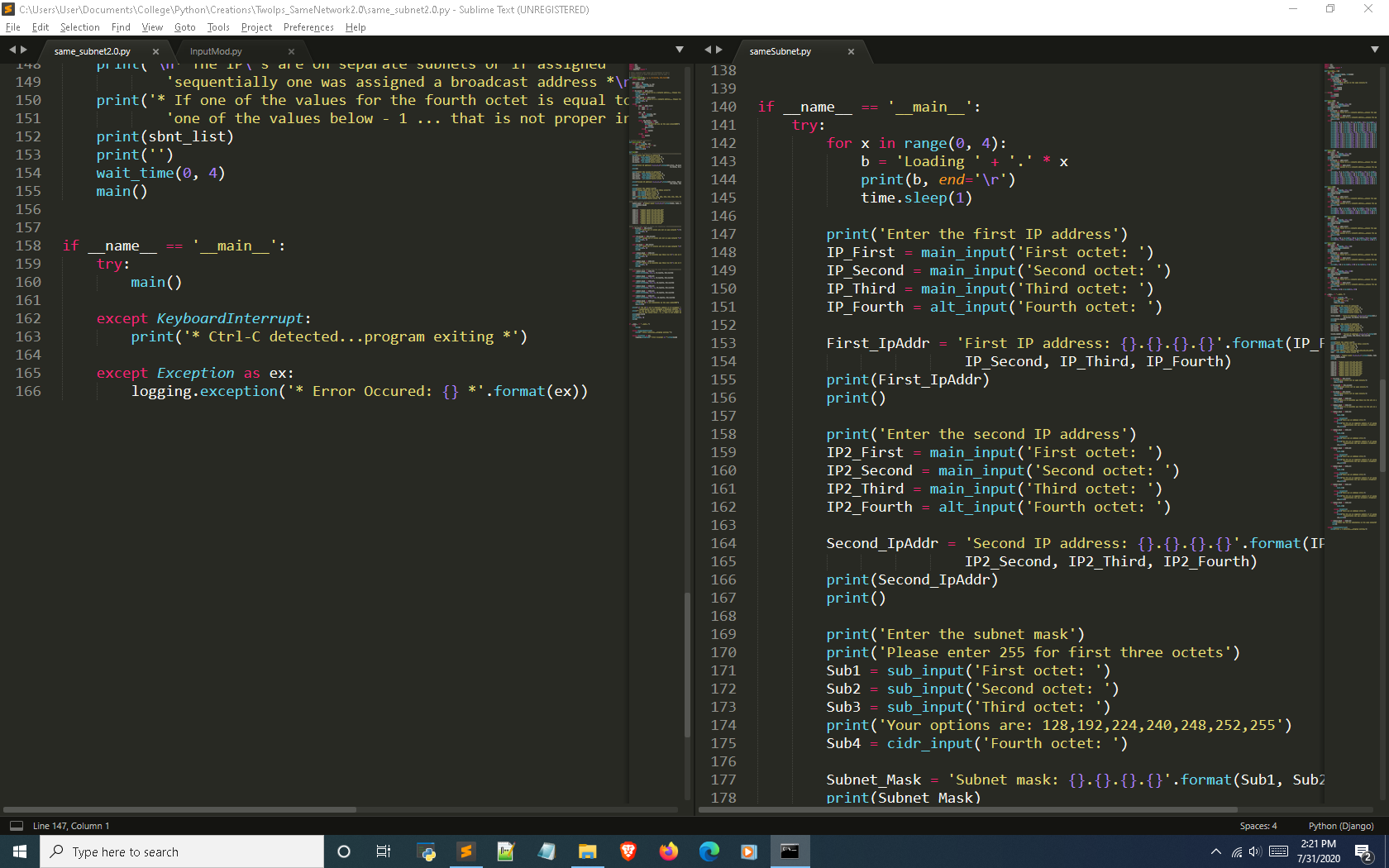
Improving the input sections
The screenshot below shows the sections where the user is prompted to input the IP addresses. Both use a custom input module I made that utilizes a loop to continually prompt the user for input until the desired value is entered.
The only difference is lines 141-145 on the right are placed into a function called wait_time(): due to its repetitive use with the looping transition.
After that, the user is prompted to enter the subnet mask. Considering this program is intended only for covering CIDRs /30 – /24; the program then confirms the first three octets of the IP addresses entered are identical and the mask entered is not above CIDR /30. This section is another way to handle inputs that are not logically possible for subnetting.

Function Allocation
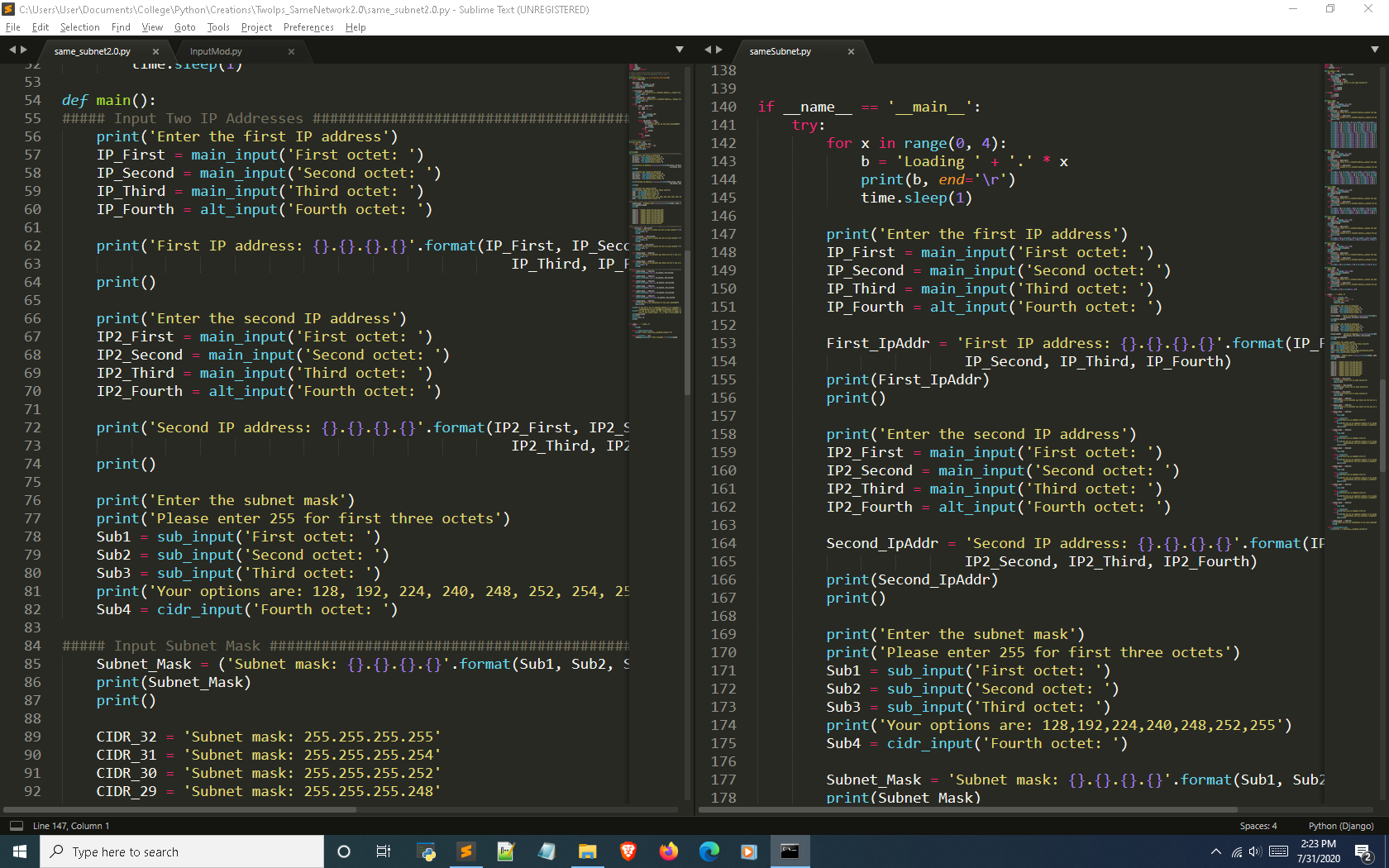
This section is where the two versions of this program really start to vary.
When taking a look over what we have covered thus far; the older version just has a bunch of if statements that work like buckets to catch all the possible inputs similar to the way that except statements work in try - except conditionals with errors.
Then each possible subnet mask is handled through own specialized function. The newer version is simple if - elif conditional where it loops back to the beginning if a subnet mask is matched but the IPs are not in the same subnet because the user entered a broadcast address which is not an assignable IP.
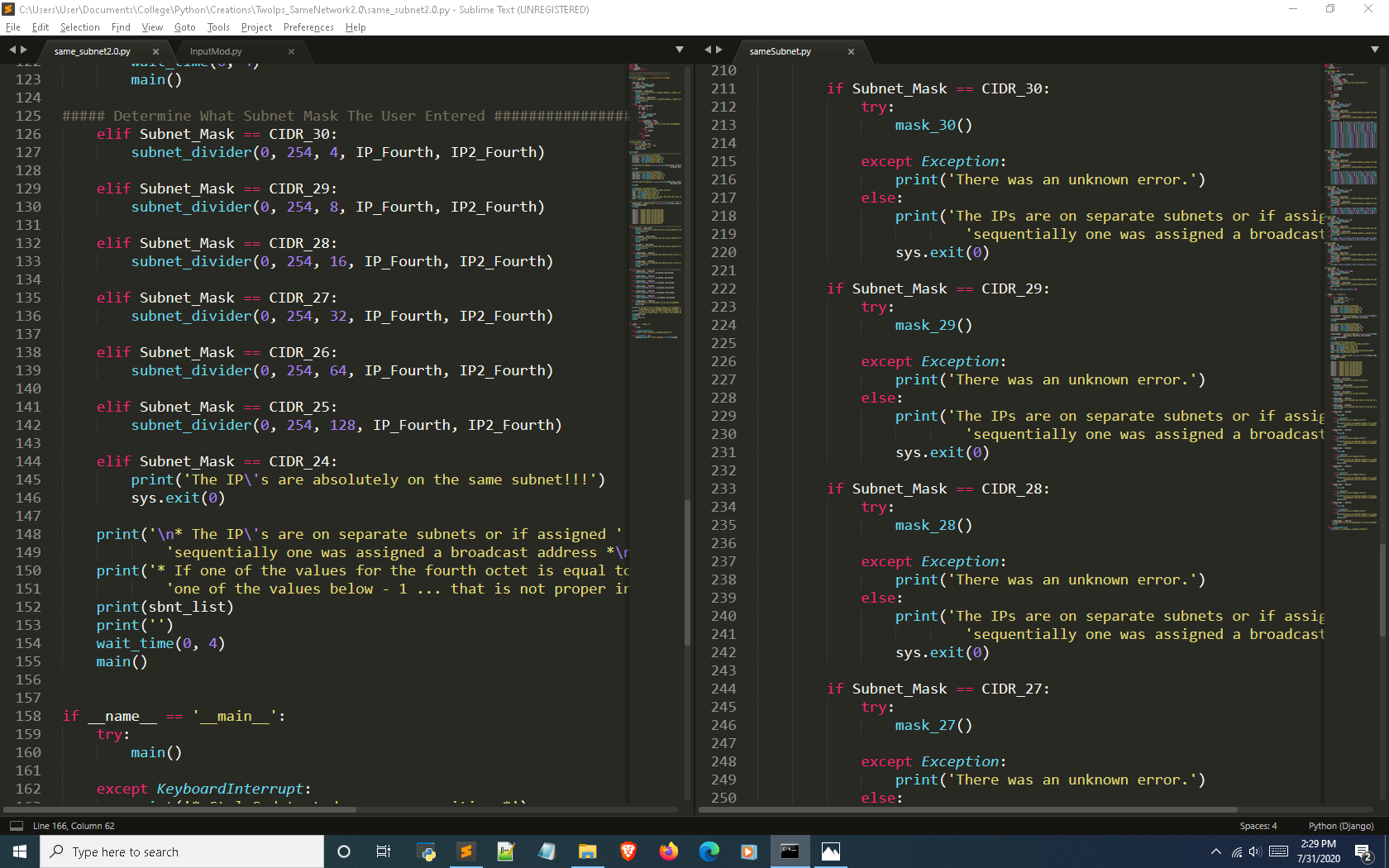
This next screenshot shows the wait time function I mentioned earlier selected on the left.
On the right side it shows the mask function which creates a range of subnets for the selected CIDR and appends them to a list of network addresses.
It then confirms that the fourth octet for both IP addresses are not in the list of network addresses. Then it is passed in another function that searches the range in between the network and broadcast address in each subnet to validate whether both IPs in the fourth octet are within that range.
If you look at this process in the older version it is frequently repeated per CIDR function. When I approached version 2.0 my goal was to find a way to feed a range into a single function to get rid of the redundant code.
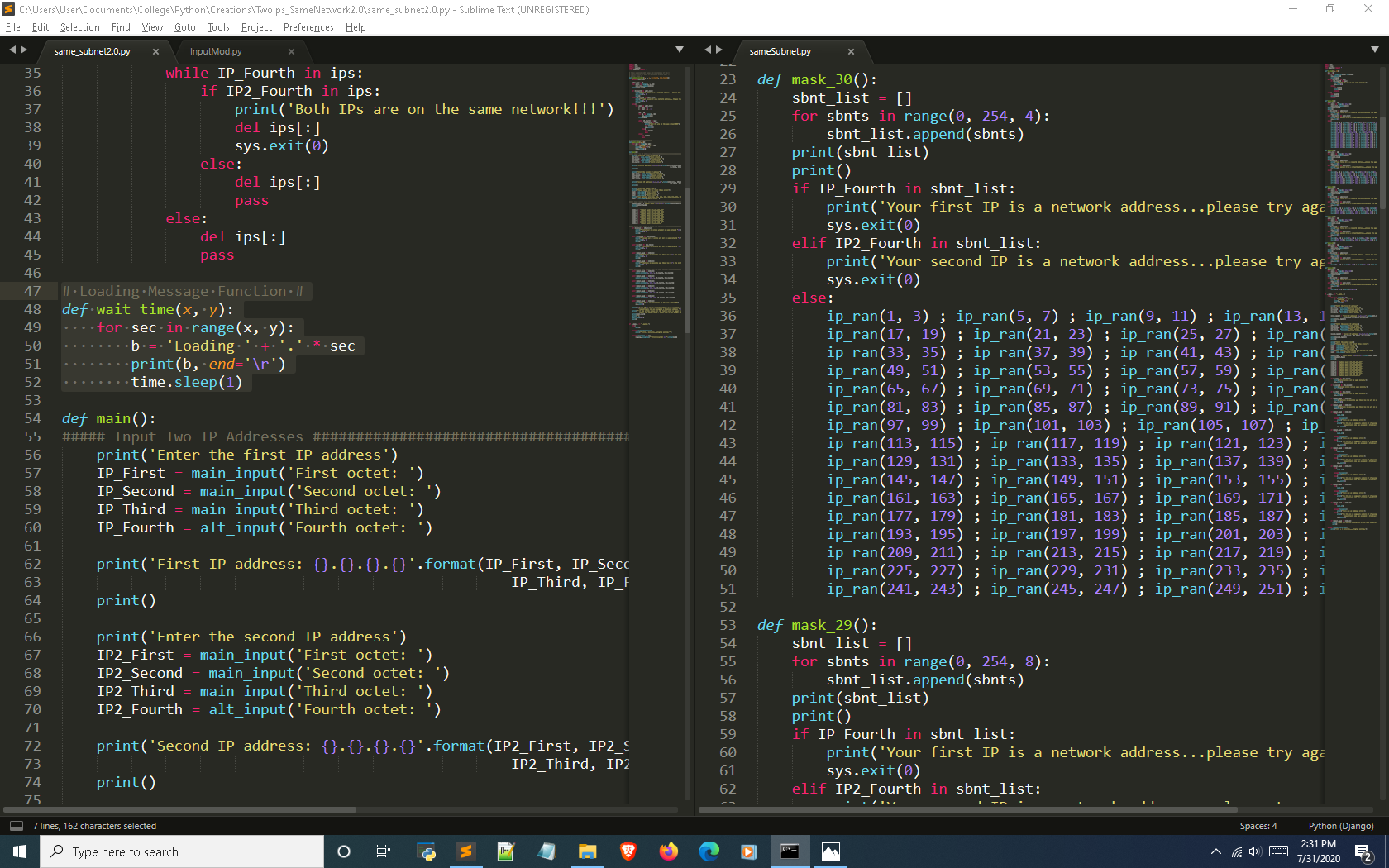
Simplifying the process
This final screenshot is what really shows how I trimmed so much fat off of the original version of this project.
When looking at the subnet_divider(): function on the left; the code up the else in the statement should look incredibly familiar to the mask function I just described.
That’s because it is almost exactly the same except the wait_time(): function and looping back to the beginning.
The only difference is the else statement which the mechanics of this function are very similar to the ip_ran(): function. The big difference that simplified and improved version 2.0 is that all the subnet ranges are passed into a singular function that manipulates the passed in range to search in between the start (network address) and stops 1 value before the next increment (broadcast address).
If this is done then there is no need for individual functions for each subnet mask and they are all accurately treated equally based on the range that is passed into the subnet divider function.

Final thoughts
I hope you found this tutorial on how I improved and refactored my Python subnet calculator helpful and use it as a resource when running into similar issues.
Make sure to mess around with both versions and see how they compare. In my opinion, if it’s possible to achieve the same with less, that is the way to go. Version 2.0 of this program has features the original doesn’t such as smooth looping to beginning instead of exiting. It also has at least 40% less code than the original!



Responses